SpringBoot + Zipkin 을 활용한 트레이스 환경 구성
샘플코드는 하기 링크로 확인
MSA 환경과 OpenTracing
모놀리식 아키텍쳐의 경우 하나의 서버가 서비스의 전반적이 기능을 모두 제공하므로 클라이언트의 요청을 받으면 하나의 스레드에서 모든 요청을 실행하여 로그를 확인하기 쉽다. 반면에 MSA 는 여러개의 마이크로 서비스 간에 통신이 발생하기 때문에 로그를 확인하기 어렵다.
이와 같은 문제를 해결하기 위한 방법으로는 OpenTracing 이 알려져 있다. OpenTracing 는 애플리케이션 간 분산 추적을 위한 표준이라고 정의할 수 있으며, 이 표준의 대표적인 구현체로 Jaeger 와 Zipin 이 있다. (다른 방법으로는 APM (Ex: Jennifer, Pinpoint 등..) 도구를 사용한 방법이 있지만 상세한 추적이 어렵다고 한다)
그러므로 Java 와 Spring 프레임워크 환경에서 쉽게 연동할 수 있는 Zipkin 으로 선택한 내용을 보고 정리하기로 하였다.
Zipkin
Zipkin 이란 분산 환경에서 로그 트레이싱하는 오픈소스로 트위터에서 개발되었으며, 현재 가장 활성화된 오픈소스라고 한다. (플러그인 또는 부가적인 도구가 많음). Zipkin 으로 추적할 수 있는 분산 트랜잭션은 HTTP, gRPC 가 있다.
Zipkin 의 아키텍쳐는 아래와 같다.
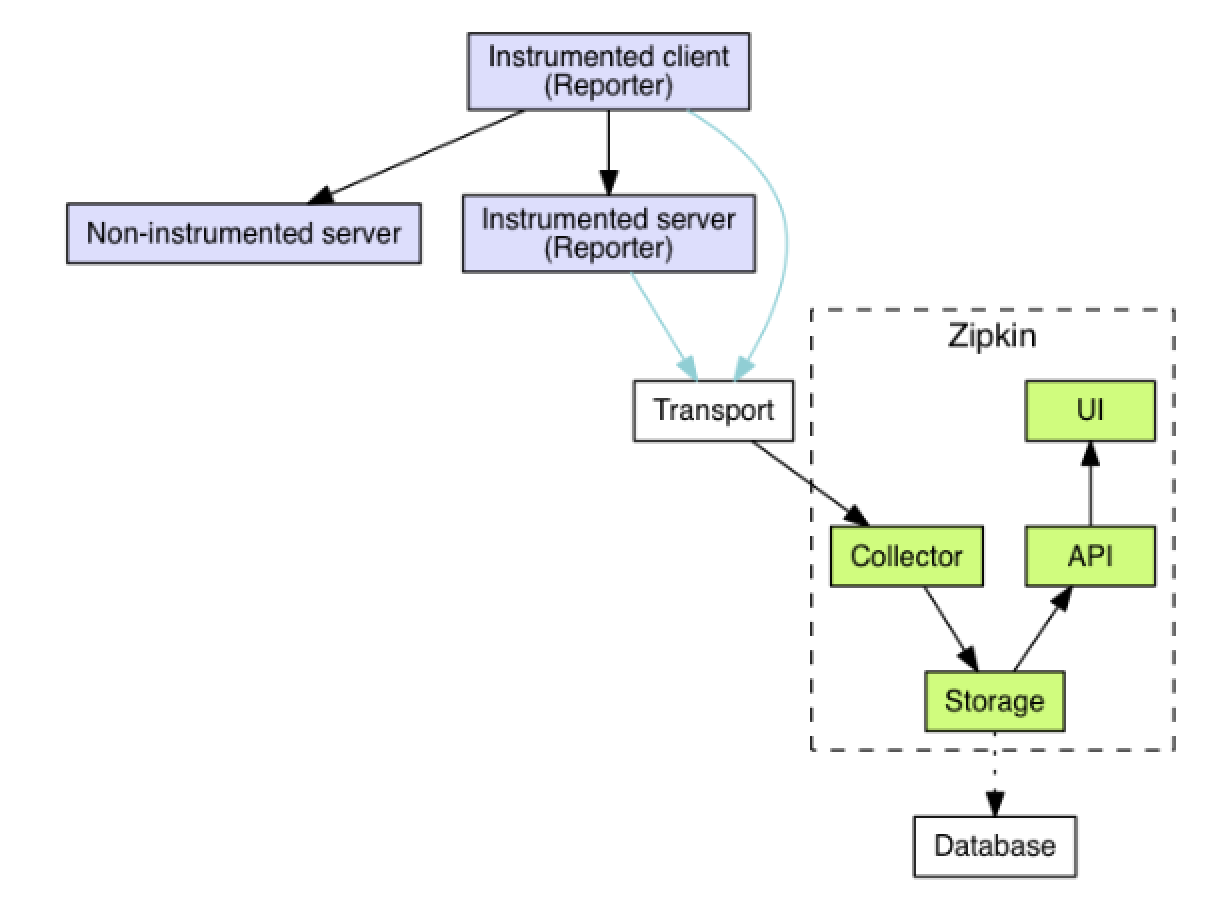
Reporter가 Transport 를 통해서 Collector 에 트레이스 정보를 전달한다.- Reporter
- 각 서버는 계측(instrumented) 라이브러리를 사용해야 Reporter 로서 동작할 수 있다고 한다. Zipkin 에서는 다양한 언어에 대한 라이브러리를 제공하며 Java 환경이므로 Brave 를 사용할 수 있으며 또한 Spring 프레임워크에서는 Spring Cloud Sleuth 의 BraveTracer 를 통하여 트레이스 데이터를 관리하기 위한 기능들을 제공하고 있어 쉽게 적용할 수 있다.
- Reporter
- 전달된 트레이스 정보는 Database 에 저장된다.
- Database
- Zipkin 에서 몇 가지 Storage 를 지원하며, 그 중 ElasticSearch 를 선택하여 진행하기로 하였다.
- Database
- Zipkin UI 에서 API 를 통해 해당 정보를 시각화해서 제공한다. (하기 명령으로 간단하게 구성할 수 있다.)
$ curl -sSL https://zipkin.io/quickstart.sh | bash -s $ java -jar zipkin.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=http://127.0.0.1:9200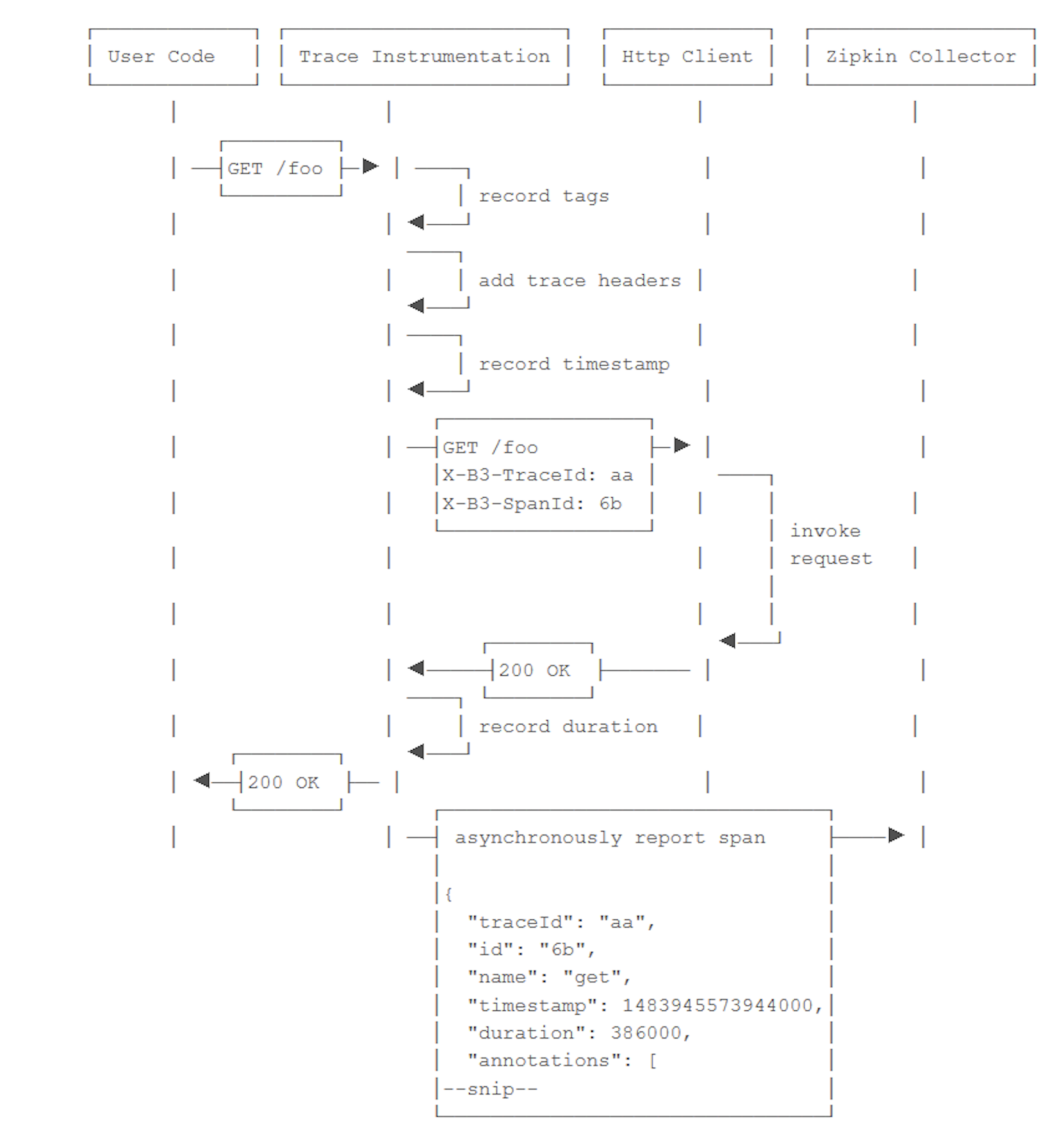
Zipkin 을 실행하면 하기 이미지 처럼 실행된다. (Zipkin UI Dashboard에는 접속이 되지만, Zipkin Client Library로부터 어떠한 정보도 받지 않았기 때문에 아무런 데이터도 나오지 않는다.)

Spring Cloud Sleuth
Spring Boot 환경에서 Spring Cloud Sleuth 를 사용해보자.
Zipkin 은 B3-Propagation 을 통하여 OpenTracing 을 구현하고 있다. Client 에서 HTTP Header 를 통하여 다른 서버로 전달하고, 예를 들어 Kafka 메세지를 통해 전달하는 경우에는 Kafka 헤더를 통해서 전달하면 Header 의 X-B3- 으로 시작하는 X-B3-TraceId, X-B3-ParentSpanId, X-B3-SpanId, X-B3-Sampled 총 4개 값을 전달하여 트레이스 정보를 관리한다.
Spring Cloud Sleuth 설정
필요버전
- java11
- spring boot 2.2.2.RELEASE
의존성 추가
build.gradle 에 의존성 추가 (각 서비스에 추가)
...
dependencies {
...
implementation group: 'org.springframework.cloud', name: 'spring-cloud-starter-zipkin', version: '2.2.3.RELEASE'
}
application.yml 에 zipkin 과 sleuth 설정 추가 (각 서비스에 추가)
spring:
application:
name: [Zipkin UI 에서 확인할 수 있는 서비스명]
sleuth:
sampler:
probability: 1.0 # Zipkin 에 트랜잭션을 어느정도 비율로 보낼지에 대한 설정 값이며 기본값은 10%(0.1) 이며, 1.0 이면 트랜잭션을 100% 보내게 된다.
enabled: false
zipkin:
base-url: http://[Zipkin 실행 호스트 ip]:9411
enabled: false
테스트
애플리케이션을 실행하고 아무 API 를 호출하면 하기와 같이 로그가 표시된다.
[Sleuth 적용 전]

[Sleuth 적용 후]

혹시 log 에 sleuth 를 추가한 로그가 찍히지 않는다면 logback.xml 에 하기 내용을 추가하자.
[logback.xml]
...
// %X{X-B3-TraceId:-}, %X{X-B3-SpanId:-}, %X{X-B3-SpanId:-} 추가필요
<appender name="stdout" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>
%d{yyyy-MM-dd HH:mm:ss} [%thread, %X{X-B3-TraceId:-}, %X{X-B3-SpanId:-}] [Request: %X{method} uri=%X{uri} payload=%X{payload}] %-5level %logger{36} - %msg %n
</Pattern>
</layout>
</appender>
...
- %X{X-B3-TraceId:-}: trace Id (트랜잭션 ID)
- %X{X-B3-SpanId:-}: span Id (구간별 ID)
- %X{X-B3-SpanId:-}: Zipkin 전송 성공 여부
그 다음 실행했었던 Zipkin Dashboard 인 http://localhost:9411 로 접속하여 검색바에 + 버튼을 클릭하여 serviceName 을 선택 후 상기 application.yml 에 선언했던 서비스명을 입력하면 아래 이미지와 같이 조회된다.
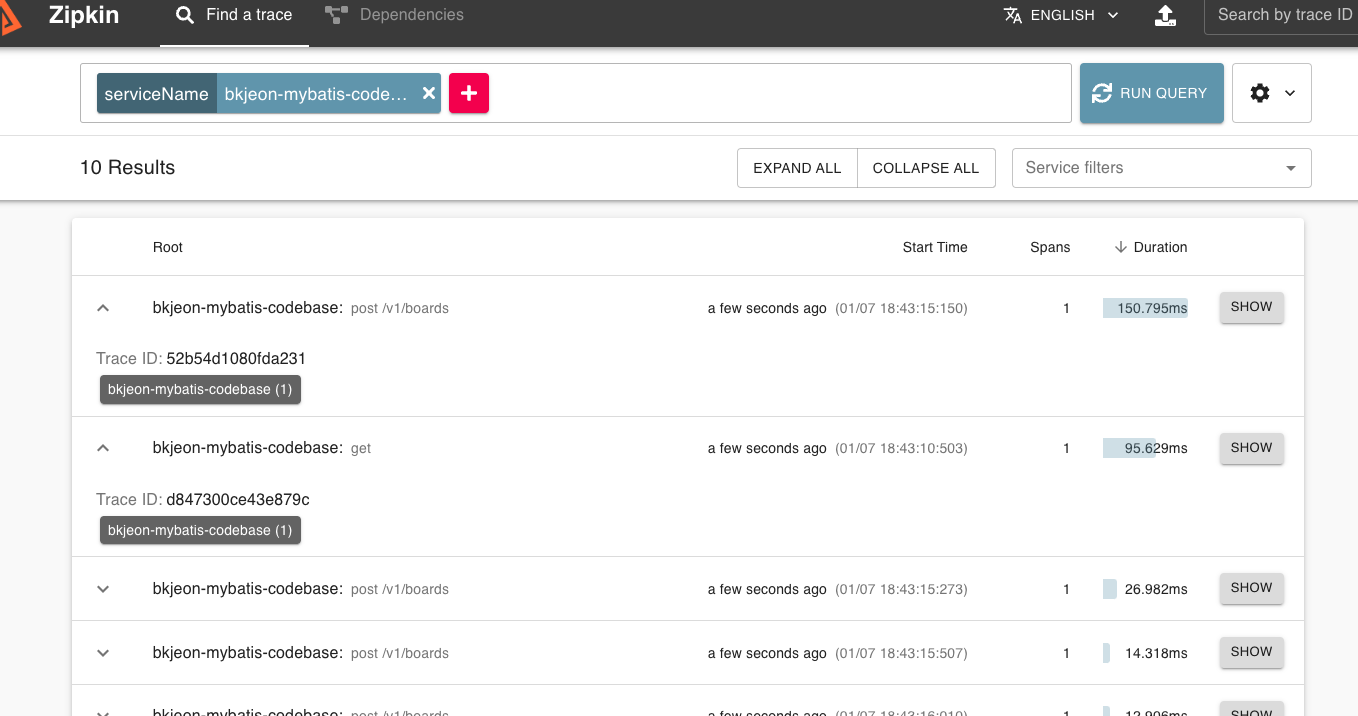
해당 이미지를 보면 bkjeon-mybatis-codebase (1) 은 bkjeon-mybatis-codebase 의 서비스에서 1건이 발생했다고 표시되며 만약에 bkjeon1 (3), bkjeon2 (1) 이라고 버튼이 표시되면 bkjeon1 에서 서비스 3건, bkjeon2 서비스에서 1건의 span 이 하나의 트랜잭션으로 묶여있다고 이해하면 된다.
또한 SHOW 버튼을 클릭하여 들어가면 자세한 내용을 볼 수 있는데 현재는 하나의 프로젝트로 진행해서 하나로만 표시되지만 여러개 서비스에 전부 적용할 경우 그 서비스들이 호출받은 대상이 새로운 호출을 만들어서 다른 서비스에 호출하는 식으로 구성되면 span 이 더 많아져서 어느 서비스가 어떻게 호출하여 시간이 얼마나 걸리고 어디를 그 다음 호출했는지 등에 대해 분산추적이 가능하다.
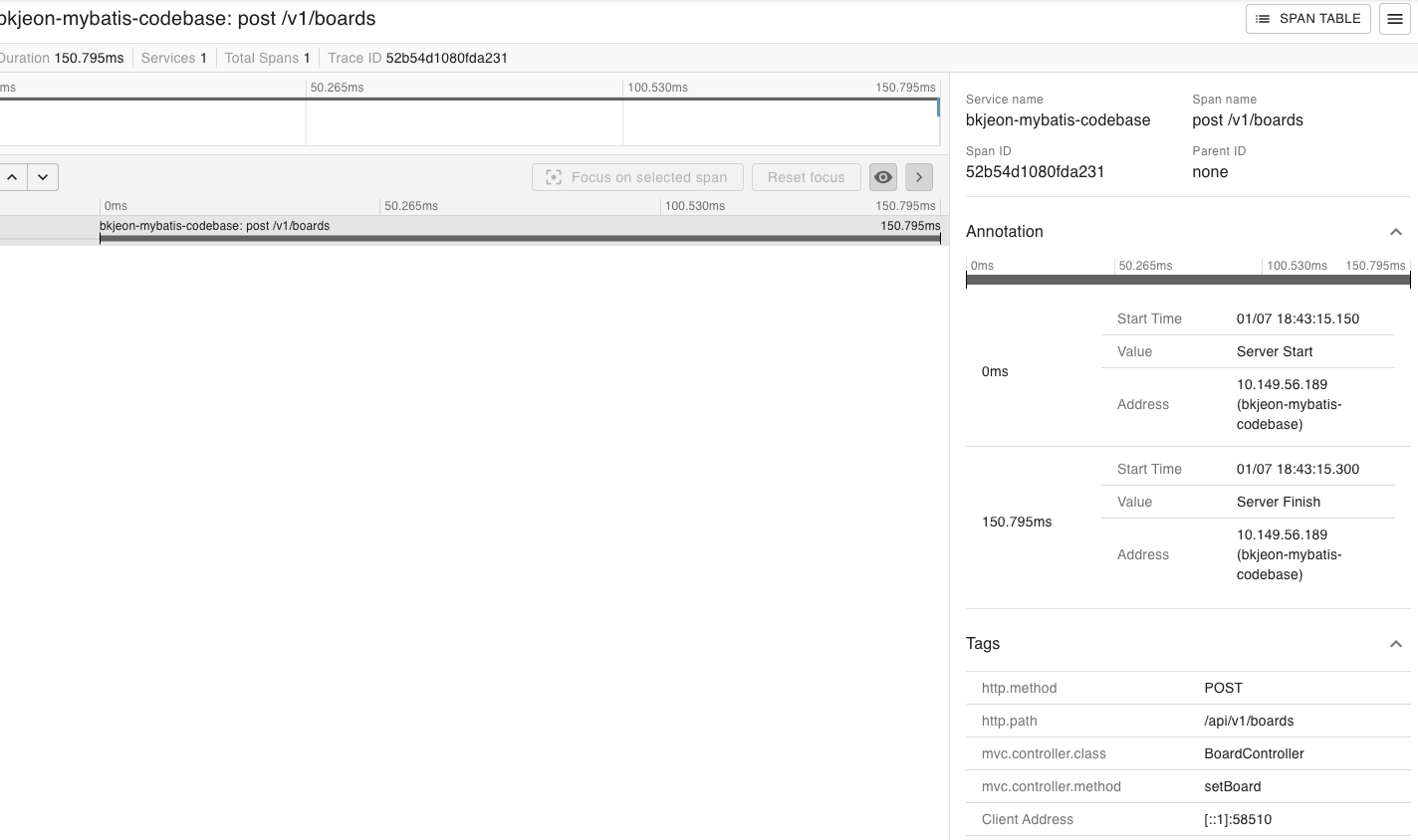
그러나 이렇게 적용을 하게되면 Zipkin 은 In-Memort 스토리지를 사용하게 되므로 Zipkin 종료 시 적재되었던 트레이싱 정보가 모두 사라지는 문제가 발생하게되므로 다음 스텝에서는 Elasticsearch, Kibana 연동하는 과정을 적용하자.
Zipkin 과 Elasticsearch, Kibana 연동
Elasticsearch, Kibana 를 Docker 를 활용하여 간단히 실행해보자.
// Elasticsearch 설치
$ docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" --name elasticsearch7 docker.elastic.co/elasticsearch/elasticsearch:7.1.1
// Elasticsearch 설정 확인
$ docker exec -i -t elasticsearch7 cat /usr/share/elasticsearch/config/elasticsearch.yml
// Kibana 설치
$ docker run -d --link elasticsearch7:elasticsearch -p 5601:5601 --name kibana7 docker.elastic.co/kibana/kibana:7.1.1
// Kibana 설정 확인
$ docker exec -i -t kibana7 cat /usr/share/kibana/config/kibana.yml
Zipkin 과 Elasticsearch, Kibana 정보설정
// 기존에 실행되었던 Zipkin 을 종료하고 해당 명령으로 -DES_HOSTS 를 설정하여 다시실행
// Ex) java -DSTORAGE_TYPE=elasticsearch -DES_HOSTS=http://[elasticsearch ip]:[elasticsearch port] -jar zipkin.jar
$ java -DSTORAGE_TYPE=elasticsearch -DES_HOSTS=http://localhost:9200 -jar zipkin.jar
Kibana 로그 확인
이제 각 서비스들의 API 호출 후 Zipkin 으로 전송한 성공여부를 확인한 후 kibana 에 접속하여 (http://localhost:5601) Management > Index Patterns > Create Index Pattern 을 클릭한 후 Index Pattern 란에 zipkin* 을 입력 후 > Next Step 을 클릭하자.
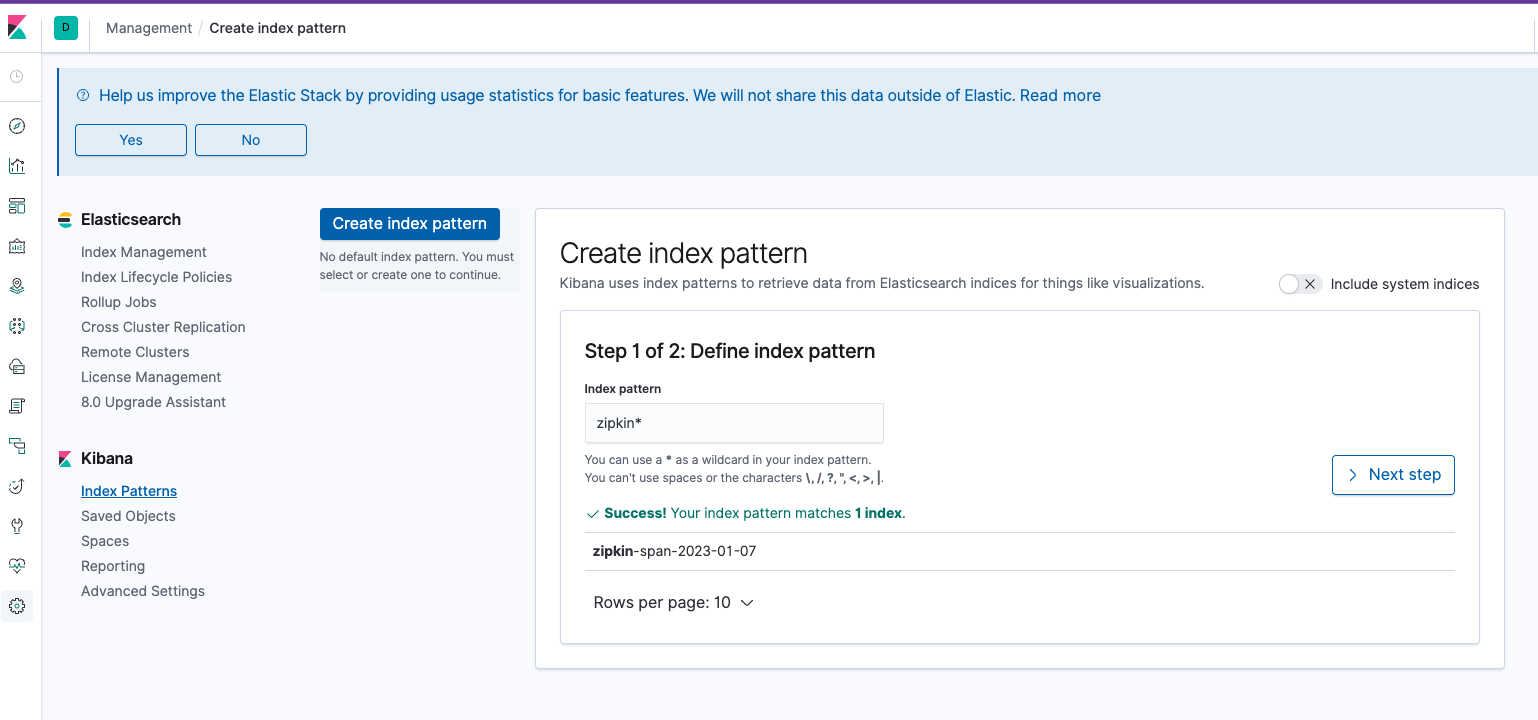
그 다음 [Time Filter field name]에서 timestamp_millis 를 선택하고 [Create index pattern] 을 클릭한다.
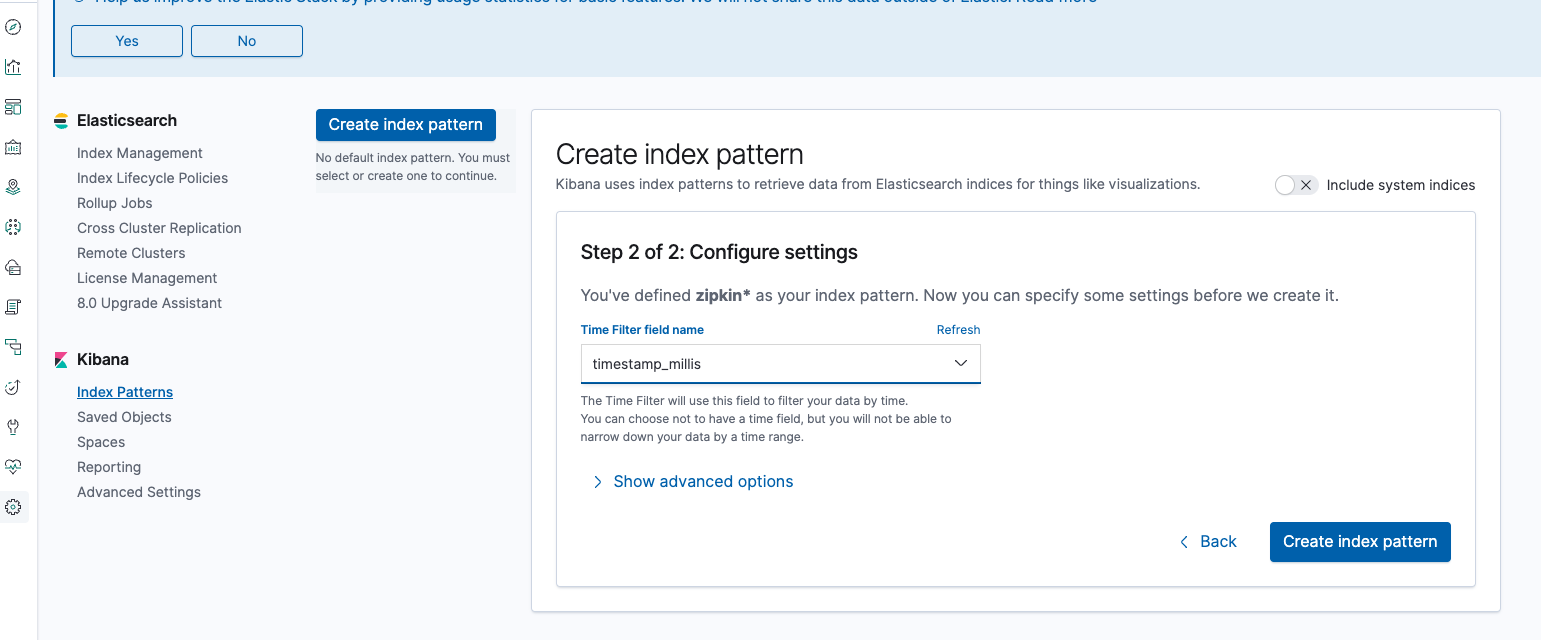
그리고나서 Kibana 메뉴에서 Discover 로 간 다음 Filter 를 방금 추가한 Index Pattern 인 zipkin 으로 변경한다.
이제 완료되면 Zipkin 을 종료했다가 다시 실행해도 Elasticsearch 에 적재된 데이터가 존재하기 때문에, 트레이싱 정보가 모두 유지되어있는걸 확인할 수 있다.
참고
- https://zipkin.io/
- https://engineering.linecorp.com/