Spring Batch 성능 개선 사례 정리
개선 항목 점검 Flow
- 유지보수가 좋고 코드가 직관적인 범주 내에서 최적화를 진행
- 이후에도 성능 이슈가 발생하면 멀티 스레드 / 파티셔닝과 같은 다양한 방식으로 진행
즉, 직관적인 방식과 단계적으로 진행하는 편이 좋다.
개선 항목
단일 UPDATE -> WHERE IN (Nos..) UPDATE 로 변경
하기 코드에서 단일로 UPDATE 를 실행하면 건별로 DB의 I/O 발생이 일어난다. 만약 WHERE IN 으로 변경시 예를 들어 1000개의 단 건일 경우 WHERE IN 으로 500개씩 나누어 처리하면 최대 2건의 I/O 발생
// 단일
UPDATE user
SET grade = 'A'
WHERE id = 1;
UPDATE user
SET grade = 'A'
WHERE id = 2;
UPDATE user
SET grade = 'A'
WHERE id = 1000;
// WHERE IN
UPDATE user
SET grade = 'A'
WHERE id IN (1,2,3...);
UPDATE user
SET grade = 'A'
WHERE id IN (3,4,5...);
UPDATE user
SET grade = 'A'
WHERE id IN (6,7,8...);
만약 여기서 포인트와 같은 유저별 다른 값들이 추가된다면 상기 WHERE IN 절로는 불가능하다. 그러면 Execute Batch 를 활용 (관련하여 코틀린에서는 Exposed 라는것이 존재한다고 한다.)
// 쿼리를 한 번에 묶어서 전송
UPDATE user SET grade = 'A' WHERE id = 1 AND point = 150;
UPDATE user SET grade = 'A' WHERE id = 2 AND point = 120;
...
PageItemReader 에서 LIMIT / OFFSET ZeroOffsetItemReader 를 통한 개선
MySQL 에서 LIMIT / OFFSET 을 사용할 경우 데이터가 많을수록 조회시 느려지거나 뻗을 경우가 발생한다.
이러한 문제점을 해결하기 위해 ZeroOffsetItemReader 방식을 사용해보자. (OFFSET 을 조회시 계속 0 으로 유지하는 Reader)
// 계속 offset 을 0 으로 유지하고 where 방식으로 구간을 정하기 때문에 속도가 느려지지 않는다.
// 기존 LIMIT OFFSET 은 앞에서 읽었던 행을 다시 읽어야 하기 때문에 성능저하가 발생하지만, No Offset 은 조회 시작 부분을 인덱스로 빠르게 찾아 매번 첫 페이지만 읽도록 하는 방식이라 성능이 좋다.
// PK 기준으로 정렬 및 범위 지정
SELECT * FROM sample WHERE name = 'TEST' and id > 0 LIMIT 0, 100;
SELECT * FROM sample WHERE name = 'TEST' and id > 1000 LIMIT 0, 100;
SELECT * FROM sample WHERE name = 'TEST' and id > 2000 LIMIT 0, 100;
...
비슷한 방식으로는 CursorItemReader 가 있으나 유형에 따라 주의해서 사용해야되는 상황도 있기 때문에 상황에 맞게 사용을 권장
- JpaCursorItemReader
- MySQL Cursor 방식 X
- 즉, 데이터를 모두 읽고 서버에서 직접 Cursor 하는 방식이므로 데이터가 많을 경우 OOM 발생
- JdbcCursorItemReader, HibernateCursorItemReader
- MySQL Cursor 방식 O
- MySQL 의 Cursor 를 사용하여 일정 개수만큼 Fetch 하는 방식이므로 안전함
- 단, Native Query 를 사용해야 구현이 가능 (Ex: Exposed 를 사용하면 된다. Java 는 사용 불가능)
그러나 해당 방법에도 단점은 존재한다.
- GROUP BY 등으로 기준으로 잡을 key 가 중복이 될 경우 정확한 결과를 반환할 수 없어서 사용 X
- 회사 정책상 More 버튼이 안되고 무조건 페이징 버튼 형식으로 한다면 사용 X
커버링 인덱스 (Covering Index) 를 통한 개선
ZeroOffsetItemReader 사용시에 단점들을 커버한 개선이다. 단, 데이터 양이 많아지고 페이지 번호가 뒤로 갈수록 Zero Offset 에 비해 느리다.
Covering Index 란 쿼리를 충족시키는 데 필요한 모든 데이터를 갖고 있는 인덱스 이며
- SELECT 절을 비롯해 ORDER BY, WHERE 등 쿼리 내 모든 항목이 인덱스 컬럼으로만 이루어지게 하여 인덱스 내부에서 쿼리가 완성될 수 있도록 하는 방식
- 이렇게 커버링 인덱스로 빠르게 걸러낸 row의 id를 통해 실제 select 절의 항목들을 빠르게 조회해오는 방법
``` // asis SELECT * FROM sample WHERE 조건문 ORDER BY id DESC OFFSET 페이지번호 LIMIT 페이지사이즈
// tobe (커버링인덱스) SELECT * FROM sample AS a JOIN (SELECT id FROM sample WHERE 조건문 ORDER BY id DESC OFFSET 페이지번호 LIMIT 페이지사이즈) as b on b.id = a.id
// tobe (커버링 인덱스가 사용된 부분은 JOIN 에 있는 쿼리이다) SELECT id FROM sample WHERE 조건문 ORDER BY id DESC OFFSET 페이지번호 LIMIT 페이지사이즈 ```
커버링 인덱스가 빠른이유
- WHERE, ORDER BY, OFFSET ~ LIMIT 를 인덱스 검색으로 빠르게 처리하고, 이미 다 걸러진 10개의 row에 대해서만 데이터 블록에 접근하기 때문에 성능의 이점을 얻게 된다.
하지만 단점도 존재한다.
- 너무 많은 인덱스가 필요
- 인덱스 크기가 너무 커짐
- 데이터 양이 많아지고 페이지 번호가 뒤로 갈수록 Zero Offset 에 비해 느림
데이터가 많을경우 Join + Group By + Sum 등 쿼리를 수행할 때 문제점
- 연산 과정이 쿼리에 의존적
- DB 부하 증가
- 데이터 누적
- 데이터 카디널리티 변경
- 쿼리 실행 계획의 변경
- 쿼리 튜닝 난이도 상승
- 쿼리 튜닝을 위한 과도한 인덱스 추가
- INSERT, UPDATE 성능 저하
- 저장 용량 증가
GROUP BY 를 포기하고 직접 Aggregation 하자
- Redis 사용
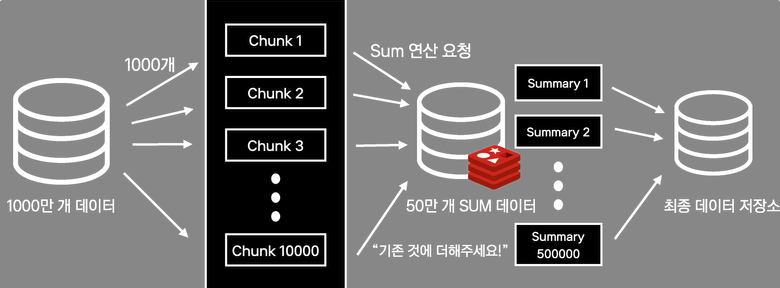
- 1000만 개의 데이터를 1000개씩 나누어 만개의 chunk 로 처리
- chunk 단위로 반복해서 Redis 에 SUM 연산 요청
- 결국에는 50만 개의 SUM 데이터가 Redis 에 들어있음
- 50만 개의 데이터를 최종 데이터 저장소에 저장
- 왜 Redis 인가?
- O(1) 연산 명령어 HINCRBY, HINCRBYFLOAT 지원
- 50만 개는 쉽게 저장하는 넉넉한 메모리
- In-Memory DB로 빠르게 저장하고 영구 저장 필요 없음
- In-Memory DB의 특성상 결과물이 디스크가 아닌 메모리에 저장돼서 연산이 매우 빠름
최종 데이터 저장소에 저장될 때까지만 유지하면 되므로 영구 저장할 필요도 없다.
- 그러나 이렇게 구성해도 레이턴시가 증가하는 이슈가 발생 (연산은 빠르게 되지만 네트워크 요청 한 번 당 1ms 라고 한다면 * 1000만번이면 3시간 즉, 전체 성능은 오히려 내려감)
- 그래서 Redis Pipeline (다수 Command 를 한 번에 묶어서 처리) 으로 처리 (Spring Data Redis 로는 처리 불가능, Batch Application 전용 Redis Pipeline 대량 처리 라이브러리 별도 개발 필요)
참고
- https://tech.kakaopay.com/post/ifkakao2022-batch-performance-read/
- https://jojoldu.tistory.com/529?category=637935
- https://www.youtube.com/watch?v=VSwWHHkdQI4&t=11s