ItemReader
이전글: Spring Batch 6편 - Chunk-Oriented Processing
작업코드: 작업코드
1. ItemReader 란
데이터 -> (읽기) -> ItemReader -> ItemProcessor -> ItemWriter -> (쓰기) -> 데이터
상기 프로세스와 같이 ItemReader 는 데이터를 읽어들인다. 꼭 DB의 데이터만 의미하진 않고 XML, JSON 등의 다른 형식의 데이터도 읽는다. 이외에도 Spring Batch 에서 지원하지 않는 Reader 들도 직접 만들 수 있다. Spring Batch 의 Reader 에서 읽어올 수 있는 유형은 아래와 같다.
- 입력 데이터에서 읽어오기
- 파일에서 읽어오기
- DB에서 읽어오기
- 다른 소스에서 읽어오기
- 직접 커스텀한 Reader 에서 읽어오기
또한 ItemReader 의 구현체를 본다고 하면 대표적으로 JdbcPagingItemReader 가 있다.
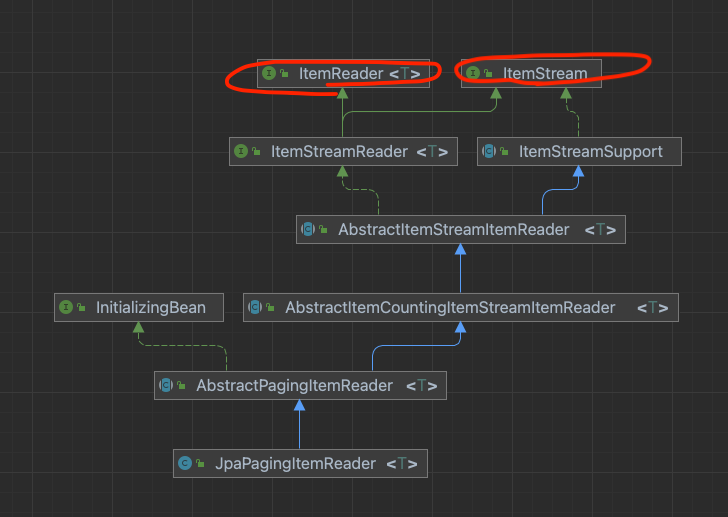
잘 확인해보면 ItemReader 이외 ItemStream 인터페이스도 같이 구현하고 있다.
또한 ItemReader 는 read() 메소드만 가지고 있고 (=데이터를 읽어오는 메소드) ItemStream 인터페이스는 주기적으로 상태를 저장하고 오류가 발생하면 해당 상태에서 복원 하기 위한 마커 인터페이스라고 한다. 즉, 배치 프로세스 실행 컨텍스트와 연계해서 ItemReader 의 상태를 저장하고 실패한 곳에서 다시 실행할 수 있게 해주는 역할이다.
ItemStream 은 3개의 메소드를 가지고 있고 각 역할은 아래와 같다.
- open(), close() 는 스트림을 열고 닫는다.
- update() 를 사용하면 Batch 의 처리 상태를 업데이트 할 수 있다.
개발자는 ItemReader 와 ItemStream 인터페이스를 직접 구현해서 원하는 형태의 ItemReader 를 만들 수 있다.
단, 본인 조회 프레임워크가 Querydsl, Jooq 라면 직접 구현해야할 수도 있다. 왜냐하면 왠만해선 JdbcItemReader 로 해결되지만,
JPA 영속성 컨텍스트 지원이 안되서HibernateItemReader 를 사용하여 Reader 구현체를 직접 구현해야 한다. 또한 이외에 다른 Reader 들을 사용할 경우 공식문서 를 참고하자.
2. Database Reader
Spring 프레임워크의 강점 중 하나는 개발자가 비즈니스 로직에만 집중할 수 있도록 JDBC 와 같은 문제점을 추상화한 것이다. 이것을 서비스 추상화 라고 한다. 그래서 Spring Batch 개발자들은 Spring 프레임워크의 JDBC 기능을 확장했다.
보통 실시간 처리가 어려운 대용량 데이터나 대규모 데이터일 경우에 Batch Application 을 사용한다.
수백만개의 데이터를 모두 불러오는 쿼리가 있는 경우 한 번에 메모리에 불러오게 된다면 어마어마한 리소스 소요가 될 것이다. 그러나 Spring 의 jdbcTemplate 은 분할 처리를 지원하지 않기 때문에 개발자가 직접 limit, offset 을 사용하는 등의 작업이 필요하다.
Spring Batch 에서는 이러한 문제점을 해결하기 위해 2개의 Reader 타입을 지원한다.
- Cursor 는 실제로 JDBC ResultSet 의 기본기능이며 ResultSet 이 open 될 때마다 next() 메소드가 호출되어 Database 의 데이터가 반환된다. 이를 통하여 필요에 따라
Database 에서 데이터를 Streaming할 수 있다.- DB -> 1 Row -> Cursor ItemReader (Cursor 를 한칸씩 옮기면서 지속적으로 데이터를 가져온다.)
- Paging 은 page 라는 Chunk 로 Database 에서 데이터를 검색한다는 것이다. 즉,
페이지 단위로 한번에 데이터를 조회해오는 방식이다.- DB -> 10 Row -> Paging ItemReader (한 번에 10개 혹은 개발자가 지정한 PageSize 만큼 데이터를 가져온다.)
상기 2개 방식의 구현체는 아래와 같다.
- Cursor 기반 ItemReader 구현체
- JdbcCursorItemReader
- HibernateCursorItemReader
- StoredProcedureItemReader
- MyBatisCursorItemReader
- Paging 기반 ItemReader 구현체
- JdbcPagingItemReader
- HibernatePagingItemReader
- JpaPagingItemReader
- MyBatisPagingItemReader
- 그 외 공식문서 에 상세하게 예제코드가 있으니 확인하면 된다.
3. CursorItemReader
CursorItemReader 는 Streaming 으로 데이터를 처리한다. (Ex: ResultSet 을 사용하여 next() 로 하나씩 데이터를 가져오는 것과 비슷)
3-1. JdbcCursorItemReader
JdbcCursorItemReader 는 Cursor 기반의 JDBC Reader 구현체이다.
하기 샘플코드를 참고하자.
[Product.java]
package com.example.entity;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@ToString
@Getter
@Setter
@NoArgsConstructor
@Entity
public class Product {
private static final DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss");
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long amount;
private String txName;
private LocalDateTime txDateTime;
public Product(Long id, Long amount, String txName, String txDateTime) {
this.id = id;
this.amount = amount;
this.txName = txName;
this.txDateTime = LocalDateTime.parse(txDateTime, FORMATTER);
}
}
[JdbcCursorItemReaderJobConfiguration.java]
package com.example.job;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcCursorItemReader;
import org.springframework.batch.item.database.builder.JdbcCursorItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import com.example.entity.Product;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@RequiredArgsConstructor
@Configuration
public class JdbcCursorItemReaderJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private static final int chunkSize = 10;
@Bean
public Job jdbcCursorItemReaderJob() {
return jobBuilderFactory.get("jdbcCursorItemReaderJob")
.start(jdbcCursorItemReaderStep())
.build();
}
@Bean
public Step jdbcCursorItemReaderStep() {
return stepBuilderFactory.get("jdbcCursorItemReaderStep")
.<Product, Product>chunk(chunkSize)
.reader(jdbcCursorItemReader())
.writer(jdbcCursorItemWriter())
.build();
}
@Bean
public JdbcCursorItemReader<Product> jdbcCursorItemReader() {
return new JdbcCursorItemReaderBuilder<Product>()
.fetchSize(chunkSize)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Product.class))
.sql("SELECT id, amount, tx_name, tx_date_time FROM product")
.name("jdbcCursorItemReader")
.build();
}
private ItemWriter<Product> jdbcCursorItemWriter() {
return list -> {
for (Product pay: list) {
log.info("Current Product={}", pay);
}
};
}
}
위 코드는 reader는 Tasklet이 아니기 때문에 reader만으로는 수행될수 없고, 간단한 출력 Writer를 하나 추가했다. 또한 위 예제처럼 reader 에서 읽은 데이터에 대해 크게 변경 로직이 없다면 processor 을 제외하고 writer 만 구현하면 된다. 즉, process 는 필수가 아니다.
JdbcCursorItemReader 의 설정값들은 아래와 같은 역할을 한다.
- chunk
<Product, Product>에서첫번째 Product 는 Reader 에서 반환할 타입이며,두번째 Product 는 Writer 에 파라미터로 넘어올 타입이다.chunkSize로 인자값을 넣으면 Reader & Writer 가 묶일 Chunk 트랜잭션 범위이다.
- fetchSize
- Database 에서 한 번에 가져올 데이터의 양
- Paging 와 는 다르게 Paging 은 실제 쿼리를 limit, offset 개념으로 분할로 처리하지만,
Cursor 는 쿼리 분할 처리 없이 실행되나 내부적으로 가져오는 데이터는 fetchSize 만큼 가져와 read() 를 통하여 하나씩 가져옴
- dataSource
- database 에 접근하기 위해 사용할 datasource 객체를 할당
- rowMapper
- 쿼리 결과를 java 인스턴스로 매핑하기 위한 mapper
- 커스텀하게 생성해서 사용할 수 있지만, 이럴 경우 매번 Mapper 클래스를 생성해야 하므로 보편적으로는 Spring 에서 공식적으로 지원하는
BeanPropertyRowMapper.class를 사용
- sql
- Reader 로 사용할 쿼리문을 사용
- name
- reader 의 이름을 지정, Spring Batch 의 ExecutionContext 에서 저장되어질 이름
ItemReader 의 큰 장점은 데이터를 Streaming 할 수 있다는 것이다. read() 메소드는 데이터를 하나씩 가져와 ItemWriter 로 데이터를 전달하고, 다음 데이터를 다시 가져온다. 이를 통하여 reader & processor & writer 가 Chunk 단위로 수행되고 주기적으로 Commit 되며 이는 고성능 배치 처리에서는 핵심이라고 한다.
이제 테이블을 생성하고 데이터를 등록하고 log를 확인하기 위해 설정을 변경하자.
[SQL]
create table product (
id bigint not null auto_increment,
amount bigint,
tx_name varchar(255),
tx_date_time datetime,
primary key (id)
) engine = InnoDB;
insert into pay (amount, tx_name, tx_date_time) VALUES (1000, 'trade1', '2018-09-10 00:00:00');
insert into pay (amount, tx_name, tx_date_time) VALUES (2000, 'trade2', '2018-09-10 00:00:00');
insert into pay (amount, tx_name, tx_date_time) VALUES (3000, 'trade3', '2018-09-10 00:00:00');
insert into pay (amount, tx_name, tx_date_time) VALUES (4000, 'trade4', '2018-09-10 00:00:00');
[application.yml]
...
logging:
level:
org:
springframework:
batch: DEBUG
배치를 실행하면 정상적으로 처리된 것을 확인할 수 있다. (Writer 에 명시한대로 로그에 출력)

주의사항
- Jpa 는 CursorItemReader 가 없다.
- CursorItemReader 를 사용할 때 Database 와 SocketTimeout 을 충분히 여유있게 설정해야 한다.
Cursor 는 하나의 Connection 으로 Batch 가 끝날때까지 사용되기 때문에 Batch 가 끝나기전에 Database 와 애플리케이션의 Connection 이 먼저 끊어질 수도 있기 때문 그러므로Batch 수행시간이 오래 걸리는 경우에는 PagingItemReader 를 사용하는게 낫다.Paging 는 한 페이지를 읽을때마다 Connection 을 맺고 끊기 때문에 아무리 많은 데이터라도 타임아웃과 부하 없이 수행될 수 있기 때문이다. (데이터가 많을 때 트랜잭션을 한번에 이어가는 것 보다 일정 주기로 여러번 실행하는 것이 안정적)
4. PagingItemReader
여러 쿼리를 실행하여 각 쿼리가 결과의 일부를 가져오는 방법을 Paging 이라고 한다. 즉, 시작 행 번호(=offset) 와 반환할 행 수(=limit) 를 지정해야 함을 의미한다.
Spring Batch 에서는 offset, limit 를 PageSize 에 맞게 자동으로 생성해준다. (단, 각 쿼리는 개별적으로 실행한다는 점을 주의하자.) 그러므로 각 페이지마다 새로운 쿼리를 실행하므로 페이징시 결과를 정렬하는 것이 중요하다. 데이터 결과의 순서가 보장될 수 있도록 order by 가 권장된다.
4-1. JdbcPagingItemReader
JdbcPagingItemRedaer 는 JdbcCursorItemReader 와 같은 JdbcTemplate 인터페이스를 이용한 PagingItemReader 이다. 하기 샘플코드를 참고하자.
[JdbcPagingItemReaderJobConfiguration.java]
package com.example.job;
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcPagingItemReader;
import org.springframework.batch.item.database.Order;
import org.springframework.batch.item.database.PagingQueryProvider;
import org.springframework.batch.item.database.builder.JdbcPagingItemReaderBuilder;
import org.springframework.batch.item.database.support.SqlPagingQueryProviderFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import com.example.entity.Product;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@RequiredArgsConstructor
@Configuration
public class JdbcPagingItemReaderJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource; // DataSource DI
private static final int chunkSize = 10;
@Bean
public Job jdbcPagingItemReaderJob() throws Exception {
return jobBuilderFactory.get("jdbcPagingItemReaderJob")
.start(jdbcPagingItemReaderStep())
.build();
}
@Bean
public Step jdbcPagingItemReaderStep() throws Exception {
return stepBuilderFactory.get("jdbcPagingItemReaderStep")
.<Product, Product>chunk(chunkSize)
.reader(jdbcPagingItemReader())
.writer(jdbcPagingItemWriter())
.build();
}
@Bean
public JdbcPagingItemReader<Product> jdbcPagingItemReader() throws Exception {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("amount", 2000);
return new JdbcPagingItemReaderBuilder<Product>()
.pageSize(chunkSize)
.fetchSize(chunkSize)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Product.class))
.queryProvider(createQueryProvider())
.parameterValues(parameterValues)
.name("jdbcPagingItemReader")
.build();
}
private ItemWriter<Product> jdbcPagingItemWriter() {
return list -> {
for (Product pay: list) {
log.info("Current Pay={}", pay);
}
};
}
@Bean
public PagingQueryProvider createQueryProvider() throws Exception {
SqlPagingQueryProviderFactoryBean queryProvider = new SqlPagingQueryProviderFactoryBean();
queryProvider.setDataSource(dataSource); // Database 에 맞는 PagingQueryProvider 를 선택하기 위해
queryProvider.setSelectClause("id, amount, tx_name, tx_date_time");
queryProvider.setFromClause("from product");
queryProvider.setWhereClause("where amount >= :amount");
Map<String, Order> sortKeys = new HashMap<>(1);
sortKeys.put("id", Order.ASCENDING);
queryProvider.setSortKeys(sortKeys);
return queryProvider.getObject();
}
}
코드를 보면 JdbcCursorItemReader 와 설정이 크게 다른것인 createQueryProvider() 가 있다. JdbcCursorItemReader 는 단순히 String 타입으로 쿼리를 생성했지만, PagingItemReader 에서는 SqlPagingQueryProviderFactoryBean 을 통하여 쿼리를 생성한다. 그 이유는 각 Database 에는 Paging 을 지원하는 자체적인 전략들이 있다. 그러므로 각 전략에 맞춰 구현해야 한다.
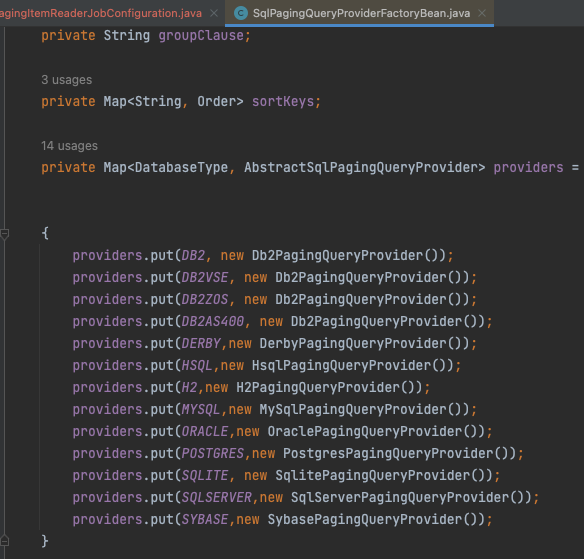
상기 전략에 맞춘 Provider 코드를 각 Database 마다 변경해야하니 번거롭다. 그러므로 Spring Batch 에서는 SqlPagingQueryProviderFactoryBean 을 통해 Datasource 설정값을 보고 위 이미지에서 작성된 Provider 중 하나를 자동으로 선택 하도록 한다. (코드 변경 사항이 적게 되므로 Spring Batch 공식 지원방법이라고 한다.)
그 외 다른 설정들의 값은 JdbcCursorItemReader 와 크게 다르지 않다.
- parameterValues
- 쿼리에 대한 매개 변수 값의 Map 을 지정한다.
- queryProvider.setWhereClause 을 보면 변수 사용법을 알 수 있다.
- where 절에서 선언된 파라미터 변수명과 parameterValues 에서 선언한 파라미터 변수명이 일치해야 한다.
실행 결과를 확인해보자.

쿼리 로그에 LIMIT 10 이 들어간 것을 확인할 수 있다. 작성한 코드에서는 LIMIT 가 없지만 사용된 쿼리에서 추가된걸 보면 위에 설명한 것 처럼 JdbcPagingItemReader에서 선언된 pageSize (Cursor에서는 fetchSize) 에 맞게 자동으로 쿼리에 추가해줬기 때문이다. (만약 조회할 데이터가 10개 이상이였다면 offset으로 적절하게 다음 fetchSize만큼을 가져올 수 있다.)
4-2. JpaPagingItemReader
JPA 사용시 Spring Batch 에서는 JpaPagingItemReader 를 공식적으로 지원하고 있다. (현재 Querydsl, jooq 등을 통한 ItemReader 구현체는 공식 지원하지 않으며 CustomItemReader 구현체를 만들어야 한다. 참고)
JPA 는 Hibernate 와 많은 유사점을 가지고 있지만, Hibernate 에선 Cursor 가 지원되지만 JPA 에는 Cursor 기반 Database 접근을 지원하지 않는다.
예제 코드를 보자.
[JpaPagingItemReaderJobConfiguration.java]
package com.example.job;
import javax.persistence.EntityManagerFactory;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JpaPagingItemReader;
import org.springframework.batch.item.database.builder.JpaPagingItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.example.entity.Product;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@RequiredArgsConstructor
@Configuration
public class JpaPagingItemReaderJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private int chunkSize = 10;
@Bean
public Job jpaPagingItemReaderJob() {
return jobBuilderFactory.get("jpaPagingItemReaderJob")
.start(jpaPagingItemReaderStep())
.build();
}
@Bean
public Step jpaPagingItemReaderStep() {
return stepBuilderFactory.get("jpaPagingItemReaderStep")
.<Product, Product>chunk(chunkSize)
.reader(jpaPagingItemReader())
.writer(jpaPagingItemWriter())
.build();
}
@Bean
public JpaPagingItemReader<Product> jpaPagingItemReader() {
return new JpaPagingItemReaderBuilder<Product>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(chunkSize)
.queryString("SELECT p FROM Product p WHERE amount >= 2000")
.build();
}
private ItemWriter<Product> jpaPagingItemWriter() {
return list -> {
for (Product product: list) {
log.info("Current Product={}", product);
}
};
}
}
EntityManagerFactory 를 지정 하는 것 외에 JdbcPagingItemReader 와 크게 다른점이 없는걸 볼 수 있다. 해당 코드를 실행해보자.
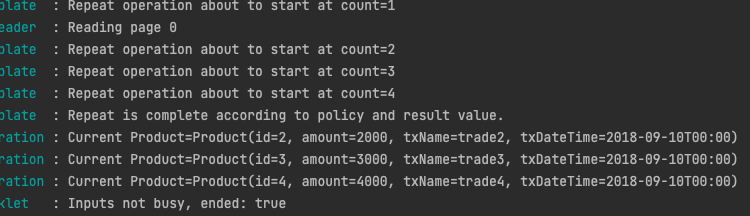
5. ItemReader 주의사항
- PagingItemReader 는 정렬(Order) 가 무조건 포함되어 있어야 한다.
- EntityManagerFactory 사용시 쿼리의 Table 명과 Entity 명의 대소문자를 일치하게 하자 (중요)
- JpaRepository를 ListItemReader, QueueItemReader에 사용하면 안된다.
- 간혹 JPA의 조회 쿼리를 쉽게 구현하기 위해 JpaRepository를 이용해서 new ListItemReader<>(jpaRepository.findByAge(age)) 로 Reader를 구현하는 경우 Spring Batch의 장점인 페이징 & Cursor 구현이 없어 대규모 데이터 처리가 불가능합니다. (물론 Chunk 단위 트랜잭션은 됩니다.)
- 만약 정말 JpaRepository를 써야 하신다면 RepositoryItemReader를 사용하시는 것을 추천 참고 (Paging 을 기본적으로 지원)
- Hibernate, JPA 등 영속성 컨텍스트가 필요한 Reader 사용시 fetchSize와 ChunkSize는 같은 값을 유지해야 한다.
참고
- https://jojoldu.tistory.com/