Java Fork Join Pool 과 비동기 프로그래밍
예제코드
Fork Join Pool 이란
ForkJoinPool 은 Java7부터 사용가능하며 동일한 작업을 여러개의 Sub Task로 분리(Fork)하여 각각 처리하고, 이를 최종적으로 합쳐서(Join) 결과를 만들어내는 방식이다. 즉, 대규모 작업을 빠르게 처리하는데 용이하다.
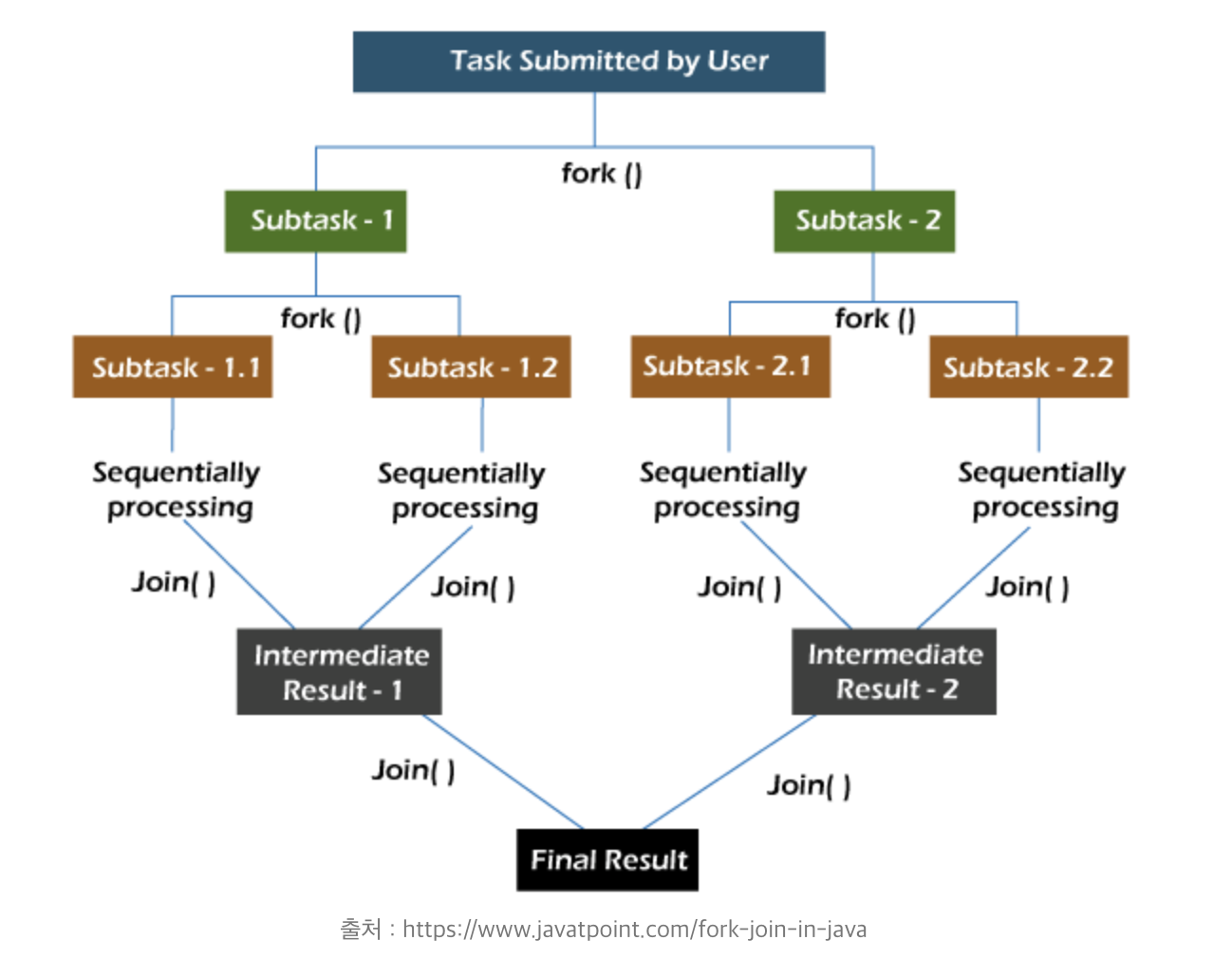
비동기 프로그래밍 (CompletableFuture, ForkJoinPool)
CompletableFuture (Java8 부터 도입)
- CompletableFuture 는 기존의 Future 인터페이스를 개선한 인터페이스다. 즉, 해당 인터페이스를 사용하면 동기적은 수행 방식을 비동기적인 수행 방식으로 변환하여 성능을 개선하고, 더 유연한 비동기 처리 로직을 구현할 수 있다.
- 비동기 호출 관련 인터페이스는 해당 포스팅을 통해 자세히 알아볼 수 있다.
예제
먼저 예제코드를 하나씩 변경해가면서 키 포인트가 되는 CompletableFuture, ForkJoinPool 가 어떻게 사용되는지 알아보자.
[Item.java]
package com.example.bkjeon.base.services.api.v1.thread;
import lombok.Builder;
import lombok.Getter;
@Getter
public class Item {
private String name;
private Integer price;
@Builder
public Item(String name, Integer price) {
this.name = name;
this.price = price;
}
}
[ItemRepository.java]
package com.example.bkjeon.base.services.api.v1.thread;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import org.springframework.stereotype.Component;
@Component
public class ItemRepository {
private Map<String, Item> storeMap = new ConcurrentHashMap<>();
public ItemRepository() {
storeMap.put("storeA", Item.builder().name("pencil").price(300).build());
storeMap.put("storeB", Item.builder().name("eraser").price(500).build());
storeMap.put("storeC", Item.builder().name("mechanical pencil").price(2000).build());
}
public int getPriceByStoreName(String name) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return storeMap.get(name).getPrice();
}
}
[ThreadController.java]
...
int priceA = itemRepository.getPriceByStoreName("storeA");
int priceB = itemRepository.getPriceByStoreName("storeB");
int priceC = itemRepository.getPriceByStoreName("storeC");
log.info("price = {}", priceA);
log.info("price = {}", priceB);
log.info("price = {}", priceC);
상기 로직은 메서드당 1초 동안 대기한 후 작업을 수행하기 때문에 총 수행시간은 3초이상 걸리게 된다. 해당 로직을 비동기로 처리하도록 변경해보자.
[ThreadController.java]
// theAccept(...): 결과를 소비하는 콜백함수로, 리턴타입이 없다. CompletableFuture.supplyAsync(...)에서의 작업이 완료된 후 결과를 처리하는 작업을 지정할 때 사용되며 만약 리턴타입이 있는 콜백 함수를 사용하고 싶다면, thenApply(...) 메서드를 사용하면 된다.
// allOf(...): 여러 CompletableFuture를 병렬로 처리할 수 있도록 해주는 메서드이며, 모든 CompletableFuture 의 처리가 완료될 때 까지 대기하며, 완료된 후 CompletableFuture<Void> 를 반환한다. 그러나 allOf 메서드는 모든 Future 의 결과를 결합한 값을 반환하지 않는다. 따라서 개별 CompletableFuture 의 결과를 사용하려면 join() 메서드를 활용해야 한다. join() 을 호출하여 allOf() 의 작업이 완료될 때 까지 블로킹하여 대기할 수 있다.
CompletableFuture<Void> priceA = CompletableFuture.supplyAsync(() -> {
log.info("ThreadName = {}", Thread.currentThread().getName());
return itemRepository.getPriceByStoreName("storeA");
})
.thenAccept(price -> log.info("price = {}", price));
CompletableFuture<Void> priceB = CompletableFuture.supplyAsync(() -> {
log.info("ThreadName = {}", Thread.currentThread().getName());
return itemRepository.getPriceByStoreName("storeB");
})
.thenAccept(price -> log.info("price = {}", price));
CompletableFuture<Void> priceC = CompletableFuture.supplyAsync(() -> {
log.info("ThreadName = {}", Thread.currentThread().getName());
return itemRepository.getPriceByStoreName("storeC");
})
.thenAccept(price -> log.info("price = {}", price));
CompletableFuture.allOf(priceA, priceB, priceC).join();
log.info("price = {}", priceA);
log.info("price = {}", priceB);
log.info("price = {}", priceC);
비동기로 변경하면 이전 동기적으로 실행한 코드보다 속도가 빨라진걸 볼 수 있다. (약 3초 -> 1초) 또한 실행 결과에는 해당 CompletableFuture 가 실행된 스레드가 ForkJoinPool.commonPool 로 표시되어 있는데 ForkJoinPool 대해 자세히 알아보자.
핵심 컴포넌트 및 동작 방식
ForkJoinPool 의 핵심 컴포넌트는 아래와 같다.
- ForkJoinPool
- ForkJoinTask 를 실행하는데 사용되는 스레드 풀로, 알고리즘 작업의 균형을 동적으로 조정하는 역할
- ForkJoinTask
- 작업의 기본 단위, 작업에는 결과를 반환하지 않는 작업(RecursiveAction) 과 결과를 반환하는 작업(RecursiveTask) 의 두 가지 형태가 존재
- Work-Stealing Algorithm
- ForkJoinPool 의 핵심 알고리즘 즉, 스레드가
다른 작업의 작업을 훔치는 알고리즘이고, 그럼으로써 모든 스레드가 유휴시간 없이 계속해서 작업을 처리할 수 있도록 한다. - 또한 이를 통하여 스레드 간의 작업 부하를 균형잡히게 유지하고, 모든 스레드가 계속 작업을 수행할 수 있도록 한다.
- ForkJoinPool 의 핵심 알고리즘 즉, 스레드가
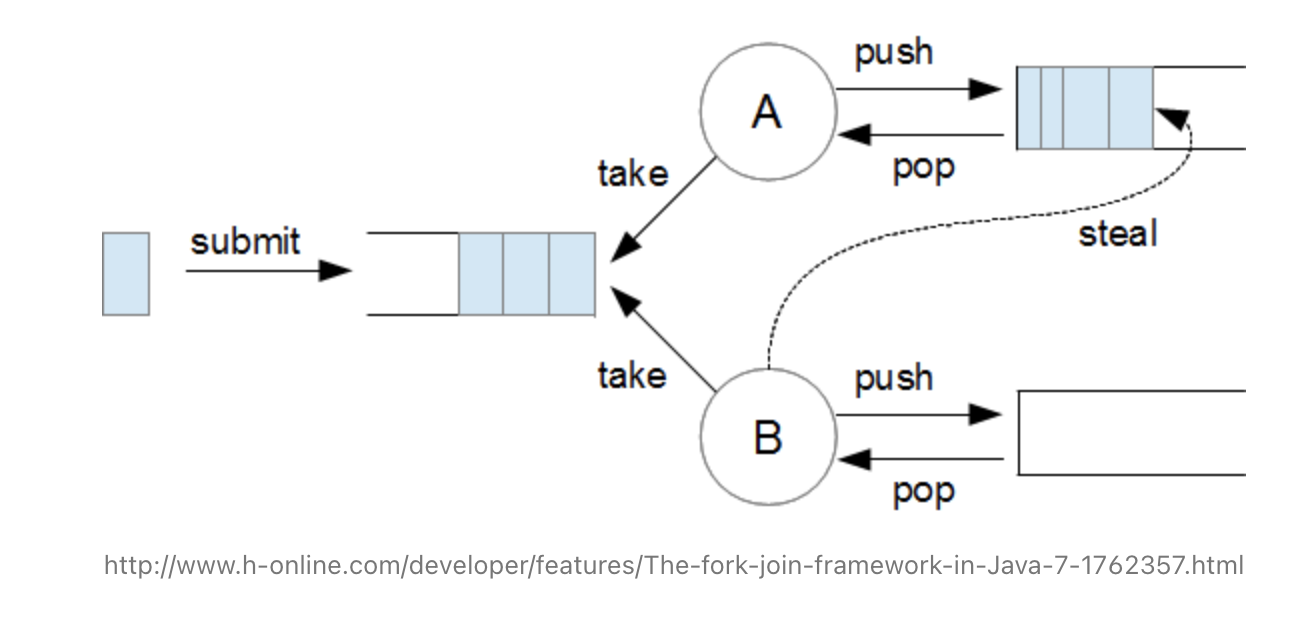
상기 ForkJoinPool 의 동작방식인 이미지에 대해 설명하면
- submit() 을 통해 task 를 보낸다.
- 인바운드 큐에 task 가 들어가고, A와 B스레드가 task 를 처리한다.
- A와 B는 각자 큐가 있으며, 상기 이미지의 B처럼 큐에 task가 없으면 A의 task를 steal하여 처리한다. (여기서 Work-Stealing 알고리즘을 사용하기 때문에 CPU 자원이 놀지 않고 최적의 성능을 낼 수 있게 해준다.)
ForkJoinPool과 CompletableFuture의 연계
Java8 부터 CompletableFuture 는 ForkJoinPool 을 사용하여 비동기 작업을 처리한다. 기본적으로 CompletableFuture 는 ForkJoinPool.commonPool() 을 사용하여 스레드풀을 가져오는데 ForkJoinPool.commonPool() 디폴트 스레드 개수 = 코어 개수 * 2 - 1 으로 기본적으로 사용 가능한 프로세서의 수에 따라 동적으로 크기가 조정되는 공용 ForkJoinPool 을 반환하며 CompletableFuture 를 사용하면 별도의 스레드 풀을 생성하거나 구성할 필요가 없이 시스템 리소스를 잘 활용한다.
ForkJoinPool 주의점
CompletableFuture와 parallelStream은 내부적으로 ForkJoinPool.commonPool()을 사용하여 작업을 병렬화 시킨다. 그렇기 때문에 commonPool을 별도의 스레드 풀로 생성하는 것이 아니다. 즉, 별도의 설정이 없다면 하나의 스레드 풀을 모든 CompletableFuture과 parallelStream이 공유하게 되고, 스레드 풀을 사용하는 다른 스레드에 영향을 줄 수 있으며, 반대로 영향을 받을 수도 있다.
- 만약 첫번 째 요청을 처리하는 동안 스레드를 점유하게 되면, 다음 요청이 도착할 때 스레드를 반환하지 않고 계속 점유하게 되어 하기 내용을 보면 결국 Thread4 만 남아 모든 요청을 처리해야 할 수 있다.
// ForkJoinPool.commonPool() 요청1-featureA: Thread1 점유중 요청1-featureB: Thread2 점유중 요청1-featureC: Thread3 점유중 Thread4 (비어있음) - 또한 Thread 가 Sleep 과 같이 아무 작업도 하지 않고 점유 중이면 심각한 문제를 초래할 수 있다. 하기 내용은 Thread4 까지 점유한 경우이고 이 경우에는 추가 요청은 처리되지 않고 Thread Pool Queue 에 쌓이게 되며, 일정 시간이 지나면 요청이 손실될 수 있다.
// ForkJoinPool.commonPool() 요청1-featureA: Thread1 점유중 요청1-featureB: Thread2 점유중 요청1-featureC: Thread3 점유중 요청2-featureA: Thread4 점유중// Thread Pool Queue 요청2-futureBTask 요청2-futureCTask
ForkJoinPool.commPool()은 전역적으로 공유되는 스레드 풀을 사용한다. 이 때문에 4개의 스레드가 모두 사용 중이라면, 다른 작업들은 대기 상태에 들어가게 되며, 특히 Blocking I/O가 발생하는 작업이 있을 경우, 스레드 풀 내부의 스레드들이 블록 되어 다른 요청들이 스레드를 얻기 전까지 기다려야 한다. 이로 인해 성능 저하와 같은 문제가 발생할 수 있다. (이러한 문제를 해결하기 위해 각 CompletableFuture나 parallelStream에 대해 독립적인 스레드 풀을 사용하는 방법이 있다.)
// new ForkJoinPool(int n) 을 사용
// 단, Parallel Stream 별로 ForkJoinPool을 인스턴스화하여 사용하면 OOM(OutOfMemoryError)이 발생할 수 있다. default 로 사용되는 Common ForkJoinPool 은 정적이기 때문에 메모리 누수가 발생하지 않지만, Custom 한 ForkJoinPool 객체는 참조 해제되지 않거나, GC로 수집되지 않을 수 있다. 이 문제는 스레드 풀을 명시적으로 종료하는 것이며 사용방법은 하기 코드처럼 forkJoinPool.shutdown(); 로 종료하자.
ForkJoinPool forkJoinPool = new ForkJoinPool(6);
forkJoinPool.submit(() -> {
integerList.parallelStream().forEach((integer) -> { ...})
}
forkJoinPool.shutdown();
CompletableFuture와 parallelStream 비교
parallelStream
java 에서 병렬처리하는 방법은 parallelStream 도 존재한다. parallelStream 도 ForkJoinPool.commonPool() 을 공유하고 병렬 처리를 지원하지만 각각 특성이 달라 적합한 곳에 사용해야 한다.
parallelStream 은 Java8 부터 추가된 Stream 의 확장으로 Stream 을 병렬로 처리할 수 있다. 하기 코드를 실행해보면 CompletableFuture 와 동일한 시간만큼 수행한다.
List<String> stores = List.of("storeA", "storeB", "storeC");
stores.parallelStream()
.forEach(store -> {
log.info("Thread Name = {}", Thread.currentThread().getName());
log.info("price = {}", itemRepository.getPriceByStoreName(store));
});
CompletableFuture와 parallelStream 차이점
만약 상기 코드를 아래와 같이 sleep 을 추가해서 코드 사이에 다른 작업이 있다고 가정하고 변경해보자.
List<String> stores = List.of("storeA", "storeB", "storeC");
stores.parallelStream()
.forEach(store -> {
log.info("Thread Name = {}", Thread.currentThread().getName());
log.info("price = {}", itemRepository.getPriceByStoreName(store));
});
Thread.sleep(1000); // 추가하면 기존보다 수행시간이 1초 늘어난 것을 확인할 수 있다.
List<Integer> prices = List.of(100, 500, 3000);
prices.forEach(price -> log.info("price = {}", price));
여기서 CompletableFuture 를 사용한 코드로 같은 상황을 재현해보자.
// 해당 코드처럼 CompletableFuture 를 사용하면 이전 parallelStream 와 다르게 1초대의 빠른 수행시간을 보여준다. 결론적으론 parallelStream 은 병렬로 실행되긴 하지만 스트림의 모든 요소가 처리될 때까지 기다려야 한다. 즉, 모든 요소가 완료될 때까지 block 된다. 반면 CompletableFuture 는 I/O 와 같은 시간이 걸리는 작업을 비동기적으로 요청한 후, 다른 작업을 수행하다가 필요한 시점에 결과를 조회할 수 있다.
List<String> stores = List.of("storeA", "storeB", "storeC");
List<CompletableFuture<Integer>> futures = stores.stream()
.map(store -> CompletableFuture.supplyAsync(() -> itemRepository.getPriceByStoreName(store)))
.collect(Collectors.toList());
Thread.sleep(1000);
futures.stream()
.map(CompletableFuture::join)
.forEach(price -> log.info("price = {}", price));
결론적으론 parallelStream은 데이터의 컬렉션 처리, 필터링, 변환과 같은 병렬 데이터 처리 작업에 적합하고, CompletableFuture는 비동기 작업, 네트워크 호출과 같은 비동기 작업의 조합이 필요할 때 적합하다는 것을 알 수 있다. 또한 재차 강조하자면 ForkJoinPool.commonPool()로 전역적으로 제공되어 문제를 발생시킬 수 있어 요청마다 스레드 풀을 만들어 사용하는 방식을 사용것이 좋다.
마지막으로
작업 분할 및 작업 스틸링에는 일정한 오버헤드가 있다. 상황에 따라 단순 threadPoolExecutor 를 사용하는 경우가 더 성능이 좋을 수 있다. (예를 들어 스레드가 4개인 경우 4개의 스레드가 동일한 일을 하게 된다면 오히려 독이지만 하나의 스레드가 굉장히 오래 걸리고 나머지 3개의 스레드가 금방 끝이나는 경우에 적합하다.)
참고
- https://kkang-joo.tistory.com/
- https://upcurvewave.tistory.com/
- https://junghyungil.tistory.com/
- https://jwooo.tistory.com/